This post was created to document the process of creating a Google Chrome Dev Tools extension which will allow a web application or plugin developer to get real time log information in the browser while developing. This first post will cover creating the web application which will log information to the dev tools extension. The second post will talk about creating the dev tools extension and connecting to the application.
What is this really about?
If you visit a site like bugs.mysql.com you will notice it tells you how long it took to generate the page. In my case it said this “Page generated in 0.017 sec. using MySQL 5.6.15-enterprise-commercial-advanced-log”. There are basically two types of logs, the ones that are persisted somehow on the server and others that are sent back to the client somehow. The mysql bugs page is an example of the latter. In this post I will be talking about the sending relevant information back to the client independent of any specific requests.
Ajax has changed everything
When I did constant WordPress development, there were many times my blog/app did not behave the way it was supposed to and I had no way of seeing what was going on. I eventually created a plugin which not only outputted all the request data, it also allowed me to output arbitrary logs, warnings, errors and sql statements together with the generated page. Fast forward to today where the apps I work on are about 90% asynchronous and views are handled on the client side, it is no longer convenient to simply output some arbitrary html/javascript to the bottom of every page. To solve this problem we need two things:
- A way to transport the debug/log information to the client
- A way to display that debug/log information on the client side once it is received
The first can be satisfied by making use of real time protocols such as WebSockets. This will continue to report back to the client even when a request fails. The second can be satisfied by creating a dev tools extension which will receive and display the debug/log information. Again this log lives in the browser and therefore will be independent of individual page requests.
A real use case
For the past couple years I have worked with asp.net mvc and entity framework quite a bit. Two common task I have are to figure out why certain records aren’t showing up on a given screen and why a given feature is slow. Part of my process is opening up sql profiler and logging any relevant sql queries which come in from the app. With this I can see whether or not the correct filters were applied via where clauses and also how long each individual query took to run. This works ok except that it is yet another window I need to open on my already crowded screen and it isn’t always easy to target the queries I am interested in. So what if instead of opening sql profiler, my sql statements came back to a neat little console in the browser where I am working? All I would have to do is open up dev tools and I would see all the sql activity as it happened. So in effect what I am looking for is a sql profiler but in the browser. One that only shows me relevant information.
Technology options
Before I go on, please note that my chosen technologies are strictly based on the fact that I develop mostly in asp.net mvc on sql server. However, this sort of thing can be done using Node.js and Socket.io or even Mono and XSockets.NET. So although I am doing this using SignalR, my proof of concept was actually done with Node.js and Socket.io.
Implementing the server side
The real time part of this is very simple because SignalR is really easy to setup and use in an application. You won’t even break a sweat adding it after the fact. For logging the sql statements, we will make use of the new interceptor api introduced in entity framework 6.
We will start off by creating a new asp.net mvc 5 project in visual studio
Once the project has been created use the package manager console or the Nuget GUI to add the latest SignalR (2.0+ id:Microsoft.AspNet.SignalR), EntityFramework (6.0+) and jQuery(2.0+) to the project. Next create a new class which will act as the SignalR bootstrapper
[assembly: OwinStartup(typeof(RealTimeLogging.SignalRStartup))]
namespace RealTimeLogging
{
public class SignalRStartup
{
public void Configuration(IAppBuilder app)
{
app.MapSignalR();
}
}
}
Next create the SignalR hub by creating a new class which extends Microsoft.AspNet.SignalR.Hub
namespace RealTimeLogging
{
public class LoggingHub : Hub
{
}
}
The next class will allow us to send messages via any SignalR hub from anywhere in the application. This class can actually be used for any hub.
namespace RealTimeLogging
{
public static class HubCaller
{
public static void Invoke<THub>(Action<IHubContext> action) where THub : IHub
{
var context = GlobalHost.ConnectionManager.GetHubContext<THub>();
action.Invoke(context);
}
}
}
Next create a class which implements the IDbCommandInterceptor interface. This class will be used to intercept entity framework DbCommands and results and send the sql statements down to the client via our SignalR hub.
namespace RealTimeLogging
{
public class StatementLogger : IDbCommandInterceptor
{
void IDbCommandInterceptor.NonQueryExecuted(System.Data.Common.DbCommand command, DbCommandInterceptionContext<int> interceptionContext)
{
SendToClient(command.CommandText);
}
void IDbCommandInterceptor.NonQueryExecuting(System.Data.Common.DbCommand command, DbCommandInterceptionContext<int> interceptionContext)
{
SendToClient(command.CommandText);
}
void IDbCommandInterceptor.ReaderExecuted(System.Data.Common.DbCommand command, DbCommandInterceptionContext<System.Data.Common.DbDataReader> interceptionContext)
{
SendToClient(command.CommandText);
}
void IDbCommandInterceptor.ReaderExecuting(System.Data.Common.DbCommand command, DbCommandInterceptionContext<System.Data.Common.DbDataReader> interceptionContext)
{
SendToClient(command.CommandText);
}
void IDbCommandInterceptor.ScalarExecuted(System.Data.Common.DbCommand command, DbCommandInterceptionContext<object> interceptionContext)
{
SendToClient(command.CommandText);
}
void IDbCommandInterceptor.ScalarExecuting(System.Data.Common.DbCommand command, DbCommandInterceptionContext<object> interceptionContext)
{
SendToClient(command.CommandText);
}
void SendToClient(string sql)
{
HubCaller.Invoke<LoggingHub>(_c => _c.Clients.All.onSql(sql));
}
}
}
The above interface gives us access to more than than just sql statements so the possibilities for adding to this class are endless. However, let us just keep it simple for now. Once registered with entity framework, the above class will send the command text of all DbCommands it receives to the client. There are several issues with the current implementation which we can fix later. The first is we assume all CommandText is sql. Another is we are sending messages to everyone instead of just the current user.
Next we will create an Entity Framework Code-First database and a client page to initiate queries so we have something to log.
Entity:
namespace RealTimeLogging
{
public class Person
{
[DatabaseGenerated(DatabaseGeneratedOption.Identity)]
public int PersonID { get; set; }
[StringLength(50)]
public string FirstName { get; set; }
[StringLength(50)]
public string LastName { get; set; }
public int Age { get; set; }
}
}
Context:
namespace RealTimeLogging
{
public class PersonContext : DbContext
{
public DbSet<Person> People { get; set; }
}
}
Initializer:
namespace RealTimeLogging
{
public class DbInitializer : DropCreateDatabaseAlways<PersonContext>
{
protected override void Seed(PersonContext context)
{
context.People.Add(new Person
{
FirstName = "John",
LastName = "Doe",
Age = 55
});
context.People.Add(new Person
{
FirstName = "Jane",
LastName = "Smith",
Age = 90
});
context.SaveChanges();
}
}
}
Db config where initializer and interceptor is registered with entity framework.
namespace RealTimeLogging
{
public class DbConfig : DbConfiguration
{
public DbConfig()
{
this.SetDatabaseInitializer<PersonContext>(new DbInitializer());
this.AddInterceptor(new StatementLogger());
}
}
}
Finally, the DbContext:
namespace RealTimeLogging
{
[DbConfigurationType(typeof(DbConfig))]
public class PersonContext : DbContext
{
public DbSet<Person> People { get; set; }
}
}
Next add an empty MVC 5 controller
Create a new view for the index action in the controller:

In RouteConfig.cs change the default controller action from “Home” to “Person”.
namespace RealTimeLogging
{
public class RouteConfig
{
public static void RegisterRoutes(RouteCollection routes)
{
routes.IgnoreRoute("{resource}.axd/{*pathInfo}");
routes.MapRoute(
name: "Default",
url: "{controller}/{action}/{id}",
defaults: new { controller = "Person", action = "Index", id = UrlParameter.Optional }
);
}
}
}
Next include the SingalR client script and a section for views to inject scripts at the bottom of _Layout.cshtml.
<script src="~/Scripts/jquery-2.0.3.min.js"></script>
<script src="~/Scripts/bootstrap.min.js"></script>
<script src="~/Scripts/jquery.signalR-2.0.1.min.js"></script>
@RenderSection("scripts",false)
</body>
</html>
At this point you should be able to run the mvc web application. You can find any missing “using” statements by right clicking classes and selecting the “Resolve” option. Once you have verified that the application can build we will create some controller actions and client side javascript which will interact with our database.
Replace the contents of Views/Person/Index.cshtml with the following:
@{
ViewBag.Title = "Index";
}
<h2>Index</h2>
<button id="btnFirstPersonName">Name of First Person</button> <span id="FirstPersonName"></span><br /><br />
<button id="btnNumberOfPeople">Number of people</button> <span id="TotalPersons"></span>
@section scripts
{
<script type="text/javascript">
$(function () {
$('#btnFirstPersonName').click(function () {
$.ajax({
url: '@Url.Action("FirstPersonName","Person")',
type: 'POST'
}).done(function (data) {
$('#FirstPersonName').text(data);
});
});
$('#btnNumberOfPeople').click(function () {
$.ajax({
url: '@Url.Action("NumberOfPeople","Person")',
type: 'POST'
}).done(function (data) {
$('#TotalPersons').text(data);
});
});
});
</script>
}
Change the PersonController class to look like the following:
public class PersonController : Controller
{
PersonContext context = new PersonContext();
//
// GET: /Person/
public ActionResult Index()
{
return View();
}
public JsonResult FirstPersonName()
{
var firstPerson = context.People.FirstOrDefault();
return Json(firstPerson.FirstName + " " + firstPerson.LastName);
}
public JsonResult NumberOfPeople()
{
var numPeople = context.People.Count();
return Json(numPeople);
}
}
At this point, if you run the app and press the two buttons your app should look like the following:

Testing the Interceptor
Set a breakpoint inside the “SendToClient” method and click one of the buttons again. The app should stop at the breakpoint just like mine did. There will be several statements coming through here so you can keep going through to see the sort of commands Entity Framework sends to the database.
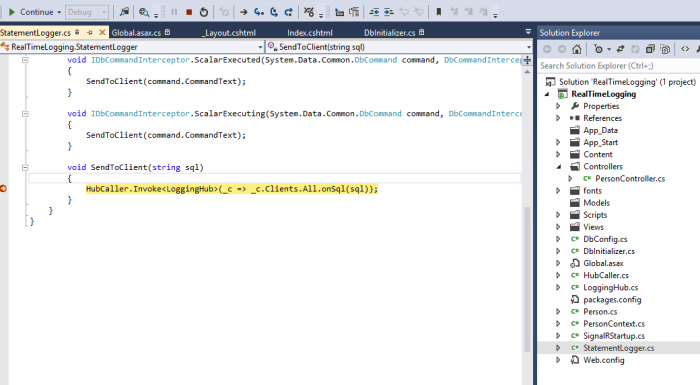
This concludes the first post which covered:
- Creating a basic Asp.net MVC 5 application
- Adding SignalR for transferring log data in real time
- Entity Framework using Code First for our database
- The new interceptor API for getting sql statements from Entity Framework
- Setting up a basic page to call some controller actions which will query the database
The code used in this post can be found on Github. The next post will cover creating the dev tools extension which will display the log information.




















